Introduction

Unlock the world of intelligent text prediction and generation with Large Language Models (LLMs), a groundbreaking technology that’s reshaping the spectrum of natural language understanding and creation in the digital realm. Navigating through the immense capabilities of models like GPT (Generative Pre-trained Transformer), businesses and developers are tapping into a rich ecosystem of applications that span across text summarization, translation, and innovative question-answering systems. With a foundation built on deep learning and robust training on diverse textual corpora, LLMs have surged as a pivotal technology, understanding and generating text that resonates with human-like context, linguistic structures, and a semblance of creative flair.
In the sphere of inference with LLMs, the technological panorama unfolds, revealing capabilities that extend beyond mere text prediction to offering coherent and contextually relevant text generation. The art and science of inference are subtly woven into the vast parameter space of these models, enabling them to meticulously predict subsequent words and generate meaningful continuations upon receiving a textual input. It’s here that LLMs shine brightly, offering businesses, content creators, and developers a tool that not only understands the inherent complexities of human language but also generates responses that are syntactically and semantically aligned with varied inputs. Explore how intelligent text generation meets practical application, providing a myriad of solutions to complex, language-based challenges across numerous domains.
Table of Contents
- Introduction
- Benefits of running inference on your own server
- Getting access to your Inference Server with GPU instances running in AWS
- Local Inference with llama.cpp
- Download a model for inference
- Using llama.cpp inference in interactive mode
- Using llama.cpp inference in server mode
- How to use LLAVA for image analysis
- How to load a full book into the prompt and query it
- Other pre-installed Use Cases on the Inference Server
- Conclusion
- Outlook
Benefits of running inference on your own server

Local inference with Large Language Models (LLMs), provides an array of advantages, particularly when considering the potential challenges that might arise with public API inference. Utilizing local resources to perform inference with LLMs enables a degree of control, agility, and security that can be pivotal in certain applications and environments.
Data Privacy
- Details: Inference ensures that sensitive or proprietary data doesn’t need to be submitted to public services and other companies or be stored, even temporarily, on servers where you do not have control.
Benefits: For industries and applications dealing with sensitive information (e.g., healthcare, finance), local inference helps maintain data privacy and comply with regulatory standards like GDPR or HIPAA.
Operational Continuity
- Details: Inference tasks can be performed without reliance on external services and APIs.
Benefits: Operations can continue unhindered ensuring consistent functionality and user experience.
Compliance
- Details: Adherence to data sovereignty and localization laws which mandate that certain types of data must reside within specific geographical boundaries.
Benefits: Local inference helps in adhering to regulatory requirements concerning data management and movement, safeguarding against legal repercussions.
Customization and Control
- Details: Executing LLMs on chosen hardware allows organizations to tailor the computational environment according to specific requirements optimizing cost and leverage their own trained LLMs.
Benefits: This means being able to optimize, modify, and manage the inference environment directly, adapting it to the unique needs of the application.
Getting access to your Inference Server with GPU instances running in AWS
In case you have a new AWS account or did not use G-instances (g4dn, g5) before you need the vCPU limit increased. You can request a quota increase for g4dn or g5 instances here: https://eu-central-1.console.aws.amazon.com/servicequotas/home/services/ec2/quotas (Documentation); the default g4dn.xlarge e.g. needs 4 vCPUs). Please make sure you request the quota increase for the right type – spot or on-demand instances (you can search for “G and” in the search bar):
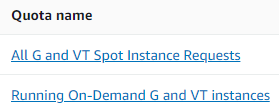
You can then access the inference server via the DCV remote desktop e.g. in your web browser or login via ssh. More background about connecting to the instance is here:
- Find the Inference server on the AWS Marketplace (all listings)
- How to start an Amazon Machine Image (AMI) with DCV: NICE DCV Remote 3D on AWS – NI SP DCV AMI (video)
- How to Connect to your AWS Cloud Server with NICE DCV (guide)
- How to grow your Disk Space in AWS Instances
Local Inference with llama.cpp

For inference we will use the very versatile llama.cpp implementation of inference on GPU and CPU. Llama.cpp offers
- Plain C/C++ implementation without dependencies
- 2-bit, 3-bit, 4-bit, 5-bit, 6-bit and 8-bit integer quantization support
- Constrain output with grammars to get exactly the output from the LLM you want
- Running inference on GPU and CPU simultaneously allowing to run larger models in case GPU memory is insufficient
- Support for CUDA, Metal and OpenCL GPU backends
- Mixed F16 / F32 precision
- AVX, AVX2 and AVX512 support for x86 architectures
- Supported models: LLaMA 🦙, LLaMA 2 🦙🦙, Falcon, Alpaca, GPT4All, Chinese LLaMA / Alpaca and Chinese LLaMA-2 / Alpaca-2, Vigogne (French), Vicuna, Koala, OpenBuddy 🐶 (Multilingual), Pygmalion 7B / Metharme 7B, WizardLM, Baichuan-7B and its derivations (such as baichuan-7b-sft), Aquila-7B / AquilaChat-7B, Starcoder models, Mistral AI v0.1, Refact
Download a model for inference

Once you are connected to your inference instance you can start downloading the first model. We download the model from HuggingFace where most of todays models are hosted. There are options like e.g. a high-end model targetting programming in different languages: https://huggingface.co/Phind/Phind-CodeLlama-34B-v2. According to the creator:
We’ve fine-tuned Phind-CodeLlama-34B-v2 on an additional 1.5B tokens high-quality programming-related data, achieving 73.8% pass@1 on HumanEval. GPT-4 achieved 67% according to their official technical report in March. Phind-CodeLlama-34B-v2 is multi-lingual and is proficient in Python, C/C++, TypeScript, Java, and more.
(https://huggingface.co/Phind/Phind-CodeLlama-34B-v2)
It’s the current state-of-the-art amongst open-source models. Furthermore, this model is instruction-tuned on the Alpaca/Vicuna format to be steerable and easy-to-use. More details can be found on our blog post.
For programming this is one of the best available models at the moment (Sept 2023). The model comes in different sizes depending on quantization from 2 – 8 bits (from https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-GGUF):
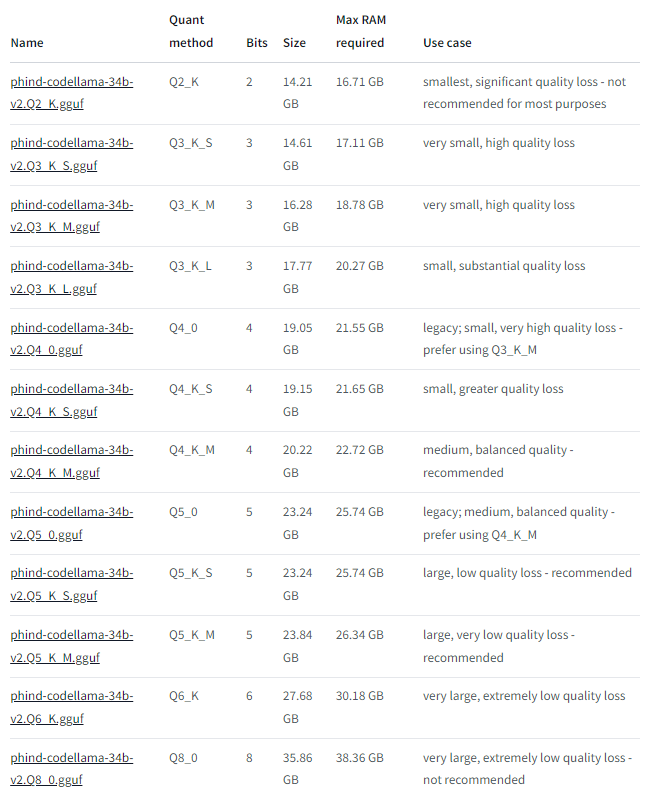
The original model is around 65 GB so we can save considerable using e.g. the Q6_K model with around 31 GB memory footprint which we can distribute on GPU and system memory in case GPU memory is not sufficient.
Another interesting model is e.g. the 70 Billion Llama2 derivate https://huggingface.co/TheBloke/OpenBuddy-Llama2-70b-v10.1-GGUF. Further models can be found at: https://huggingface.co/TheBloke.
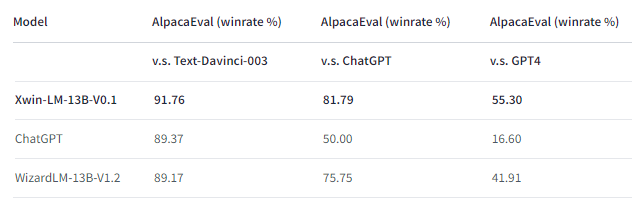
In our example below we will use xwin-lm-13b-v0.1.Q5_K_M.gguf (“Xwin has achieved 91.76% win-rate on AlpacaEval, ranking as top-1 among all 13B models.”).
To download a model you can open a terminal and enter the following commands:
# depending on your instance cd in the respective directory:
cd ~/inference/llama.cpp-g4dn # or
cd ~/inference/llama.cpp-g5
wget https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/resolve/main/xwin-lm-13b-v0.1.Q5_K_M.gguf
mv xwin-lm-13b-v0.1.Q5_K_M.gguf models/
Typically we will see a download speed of 20 – 200 MByte/sec depending on the instance size so the model is available after a few minutes. With the model available we can start preparing the inference.
As a rule of thumb – prefer a larger parameter model with lower quantization over a lower parameter model. So e.g. a 34B parameter model with quantization 4bit will perform better than a 13B parameter model with 6bit quantization.
Using llama.cpp inference in interactive mode
Here is an example how to start the llama.cpp inference in interactive mode with an explanation of parameters assuming you are in one of the directories ~/inference/llama.cpp-g*:
./main -m models/xwin-lm-13b-v0.1.Q5_K_M.gguf \
-p "Building a website can be done in 10 simple steps:\nStep 1:" \
-n 600 -e -c 2700 --color --temp 0.1 --log-disable -ngl 52 -i
# -m use the xwin-lm-13b-v0.1 model in 5 bit quantization
# -p: prompt
# -n: number of tokens to predict
# -e: process prompt escapes sequences
# -c: size of the prompt context (0 = loaded from model)
# --color: colorise output to distinguish prompt and user input
# --temp: temperature of the model output (more creative when higher; 0.8 is the default)
# --log-disable: Disable trace logs
# -ngl: how many layers to move into the GPU; depends on the amout of GPU VRAM available;
# 43 layers are equivalent to about 11.5 GB GPU memory usage including overhead
# -i: run in interactive mode
./main -m models/xwin-lm-13b-v0.1.Q5_K_M.gguf \
-p "Building a website can be done in 10 simple steps:\nStep 1:" \
-n 600 -e -c 2700 --color --temp 0.1 --log-disable -ngl 52 -i
################ output follows
ggml_init_cublas: found 1 CUDA devices:
Device 0: Tesla T4, compute capability 7.5
llama_model_loader: loaded meta data with 19 key-value pairs and 363 tensors from models/xwin-lm-13b-v0.1.Q5_K_M.gguf (version GGUF V2 (latest))
<<<model loading ...>>>
llama_new_context_with_model: kv self size = 2109.38 MB
llama_new_context_with_model: compute buffer total size = 252.09 MB
llama_new_context_with_model: VRAM scratch buffer: 246.21 MB
llama_new_context_with_model: total VRAM used: 11049.80 MB (model: 8694.21 MB, context: 2355.59 MB)
Building a website can be done in 10 simple steps:
Step 1: Choose a domain name
Step 2: Select a web hosting provider
Step 3: Design your website layout
Step 4: Develop your website content
........
At the end of the output the model has started answering our question about how to build a website.
Using llama.cpp inference in server mode
Here is an example how to start the llama.cpp inference in interactive mode (see explanation of parameter above for more background):
# --mlock: force system to keep model in RAM
./server -m models/xwin-lm-13b-v0.1.Q5_K_M.gguf \
--mlock -ngl 52 --host 0.0.0.0
<<<< output >>>>
llama server listening at http://ip-172-31-38-238:8080
If you navigate in your browser to the URL shown (with a local web browser on the desktop, or use the external IP of the instance; please make sure the port 8080 is open in the security group of the instance) you will be greeted with the following chat interface:
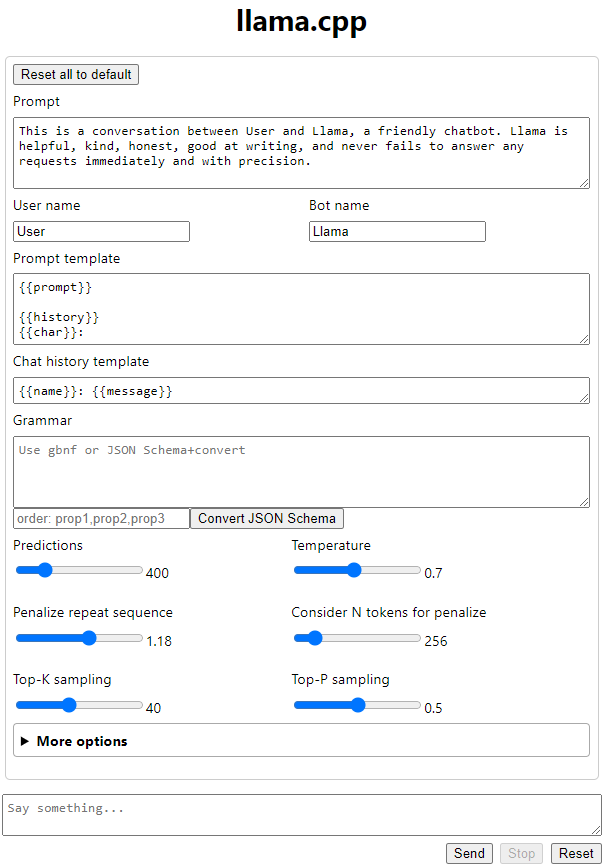
After entering a question in the lower box and hitting “Return” the inference will start showing the output from the model:

After each inference run the server will show statistics similar to below e.g. on T4 (g4dn.xlarge):
llama_print_timings: load time = 2809.78 ms
llama_print_timings: sample time = 1365.66 ms / 400 runs ( 3.41 ms per token, 292.90 tokens per second)
llama_print_timings: prompt eval time = 1181.50 ms / 229 tokens ( 5.16 ms per token, 193.82 tokens per second)
llama_print_timings: eval time = 21092.55 ms / 399 runs ( 52.86 ms per token, 18.92 tokens per second)
llama_print_timings: total time = 23774.82 ms
On the g5.xlarge instance with the faster A10G GPU you will see around 40 token/second for the eval time so roughly 2x performance compared to the T4 GPU in g4dn.
How to use LLAVA for image analysis
Llama.cpp comes with image analysis support based on the Llava implementation. Here are the steps to run Llava on your inference server:
# depending on your instance cd in the respective directory:
cd ~/inference/llama.cpp-g4dn # or
cd ~/inference/llama.cpp-g5
# Download the LLM
cd models
wget https://huggingface.co/mys/ggml_llava-v1.5-13b/resolve/main/ggml-model-q5_k.gguf
wget https://huggingface.co/mys/ggml_llava-v1.5-13b/resolve/main/mmproj-model-f16.gguf
cd ..
# Run the server:
./server -t 4 -c 4096 -ngl 50 -m models/ggml-model-q5_k.gguf --host 0.0.0.0 --port 8080 --mmproj models/mmproj-model-f16.gguf
When opening the server page via e.g. localhost:8080 on the DCV desktop with Firefox or using a ssh tunnel we can find the “Upload Image” button in the lower section of the interface:

Here is an example of an uploaded image from Pexels with description by Llava:
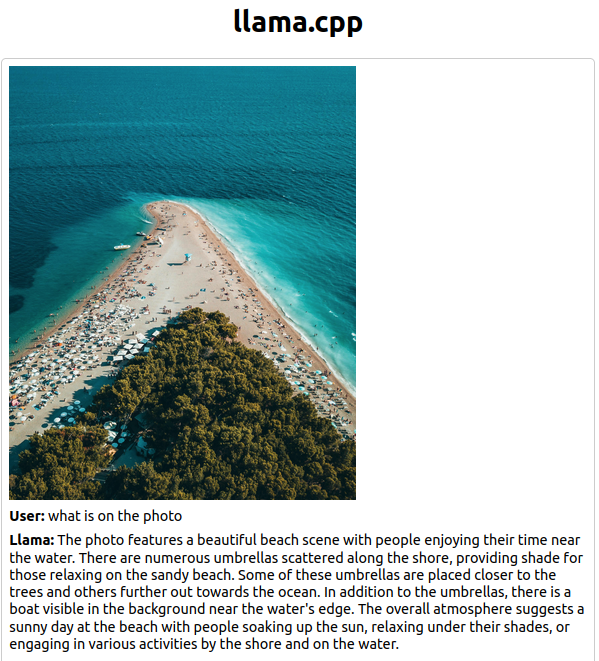
We can e.g. analyse an image similar to this with the following command:
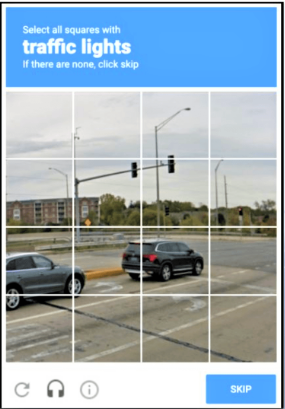
./llava -t 4 -c 4096 -ngl 50 -m models/ggml-model-q5_k.gguf --mmproj models/mmproj-model-f16.gguf --image ~/Desktop/Image\ 096.png -i -p "Describe the rectangles where traffic lights are in x1, x2 and y1,y2 box coordinates in the image"
1. [0.32, 0.35, 0.43, 0.44] - 2 red traffic lights facing opposite directions.
2. [0.51, 0.48, 0.59, 0.55] - 2 red traffic lights on the other side of the road.
3. [0.58, 0.49, 0.62, 0.54] - Red traffic light on the road.
You can also try the Bakllava LLM which works better for a number of use cases.
How to load a full book into the prompt and query it
The NousResearch/Yarn-Mistral-7b-128k model supports a context window of 128k tokens. This allows to load a large amount of text into the prompt and then work on it. Here are the steps:
wget https://huggingface.co/TheBloke/Yarn-Mistral-7B-128k-GGUF/resolve/main/yarn-mistral-7b-128k.Q8_0.gguf
mv yarn-mistral-7b-128k.Q8_0.gguf models/
# put your text e.g. a book text into "book.txt" and run
./main -m models/yarn-mistral-7b-128k.Q8_0.gguf -f book.txt -t 4096 --color --temp 0.1 \
--log-disable -ngl 52 --ctx-size 128000 -i
Other pre-installed Use Cases on the Inference Server
We have prepared additional interesting packages on the Inference Server:
OpenAI API compatible Llama.cpp server
You can e.g. download the above mentioned Phind programming model and reference this in your IDE for codepilot style support. The following command will start the llama-cpp-python OpenAI ChatGPT compatible API server (built for g4dn; building for g5, … works as well). Please remember to open the port you use below in case of remote access in the security group of the instance:
# build was done with CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
cd ~/inference/llama-cpp-python-server-g4dn; source venv/bin/activate
# please adapt your hostname (e.g. 127.0.0.1 for local network only) and the port in case
# please reference the model you want to use after --model; e.g. symlink to the local directory with ln -s MODEL .
python3 -m llama_cpp.server --n_gpu_layers 52 --use_mlock 1 --n_threads 4\
--host 0.0.0.0 --port 8080 --n_ctx 4096 \
--model xwin-lm-13b-v0.1.Q5_K_M.gguf
<<< output of model start >>>
INFO: Started server process [10576]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://ip-172-31-38-238:8080 (Press CTRL+C to quit)
INFO: client_ip:63129 - "POST /v1/chat/completions HTTP/1.1" 200 OK
llama_print_timings: load time = 1736.92 ms
llama_print_timings: sample time = 197.93 ms / 143 runs ( 1.38 ms per token, 722.50 tokens per second)
llama_print_timings: prompt eval time = 1736.81 ms / 352 tokens ( 4.93 ms per token, 202.67 tokens per second)
llama_print_timings: eval time = 7988.68 ms / 142 runs ( 56.26 ms per token, 17.78 tokens per second)
llama_print_timings: total time = 11359.74 ms
# You can build llama-cpp-python for other platforms with the following commands:
# CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python --force-reinstall --upgrade --no-cache-dir
# pip install uvicorn anyio starlette fastapi pydantic_settings sse_starlette starlette_context # in case needed
You can use this server to e.g. integrate codepilot style answering into your IDE offering ChatGPT plugins (just replace https://api.openai.com in the respective plugin with a URL similar to http://External_IP_of_instance:8080 referencing the external IP or FQDN of the instance). The advantage of the llama-cpp-python server is that you can leverage any GGUF quantized model fitting your needs.
Open Interpreter

Open Interpreter allows to automatically create code based on a prompt and execute it on the local machine after user confirmation. As the author says: “Open Interpreter lets language models run code on your computer. An open-source, locally running implementation of OpenAI’s Code Interpreter.” Here is how to use it (interpreter -h shows options):
cd ~/open-interpreter; source venv/bin/activate
# in case you have the llama-cpp-python OpenAI compatible server running (see above)
# you can use it for inference with the following command:
interpreter --api_base http://0.0.0.0:8080/v1 --ak apikey # set API key to apikey
# or use the OpenAI API in case you have an account
export OPENAI_API_KEY=PUT_YOUR_KEY_HERE
interpreter --model gpt-3.5-turbo # default is to use the GPT-4 API which is more costly
<<<< output follows >>>
▌ Model set to GPT-3.5-TURBO
Open Interpreter will require approval before running code.
Use interpreter -y to bypass this.
Press CTRL-C to exit.
> plot apple stock price since 2023
To plot the Apple (AAPL) stock price since 2023 and save it as a PNG file, we will follow these steps:
1 Retrieve the historical stock price data for Apple (AAPL) since 2023.
2 Plot the stock price data using a suitable plotting library.
3 Save the plot as a PNG file.
Let's start by retrieving the stock price data for Apple (AAPL) since 2023.
......
Open Interpreter can also run locally and download models automatically:
interpreter -h
usage: interpreter [-h] [-s SYSTEM_MESSAGE] [-l] [-y] [-d] [-m MODEL] [-t TEMPERATURE] [-c CONTEXT_WINDOW] [-x MAX_TOKENS]
[-b MAX_BUDGET] [-ab API_BASE] [-ak API_KEY] [-safe {off,ask,auto}] [--config] [--conversations] [-f]
[--version]
interpreter -l
Open Interpreter will use Code Llama for local execution. Use your arrow keys to set up the model.
[?] Parameter count (smaller is faster, larger is more capable): 7B
> 7B
13B
34B

Tabby – a self-hosted coding assistent
From the author: “Tabby is a self-hosted AI coding assistant, offering an open-source alternative to GitHub Copilot. It boasts several key features:
- Self-contained, with no need for a DBMS or cloud service.
- OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE).
- Supports consumer-grade GPUs.”
On our inference server Tabby can use the GPU enabled container support from nVidia. Starting the Tabby docker container is easy: user the following command which will download the Tabby docker image as well as the SantaCoder 1B model and start the inference server (please make sure the disk has around 4.5 GB available for container and model):
docker run -it --gpus all --network host -v $HOME/.tabby:/data tabbyml/tabby \
serve --model TabbyML/SantaCoder-1B --device cuda
<<< docker output removed >>>
Status: Downloaded newer image for tabbyml/tabby:latest
Downloaded /data/models/TabbyML/SantaCoder-1B/tabby.json
[00:00:00] [#########################################################################################] 120B/120B (415.45 KiB/s, 0s)Downloaded /data/models/TabbyML/SantaCoder-1B/tokenizer.json
[00:00:00] [##################################################################################] 1.98 MiB/1.98 MiB (13.23 MiB/s, 0s)Downloaded /data/models/TabbyML/SantaCoder-1B/ctranslate2/vocabulary.txt
[00:00:00] [#############################################################################] 398.80 KiB/398.80 KiB (138.56 MiB/s, 0s)Downloaded /data/models/TabbyML/SantaCoder-1B/ctranslate2/config.json
[00:00:00] [###########################################################################################] 99B/99B (416.61 KiB/s, 0s)Downloaded /data/models/TabbyML/SantaCoder-1B/ctranslate2/model.bin
[00:01:00] [##################################################################################] 2.10 GiB/2.10 GiB (35.53 MiB/s, 0s)
2023-10-07T17:39:42.352614Z INFO tabby::serve: crates/tabby/src/serve/mod.rs:165: Starting server, this might takes a few minutes...
2023-10-07T17:39:49.524002Z INFO tabby::serve: crates/tabby/src/serve/mod.rs:183: Listening at 0.0.0.0:8080
You can use the Tabby server to e.g. integrate codepilot style answering into your IDE like IntelliJ with the Tabby editor plugin (just replace https://api.openai.com in the respective plugin with a URL similar to http://External_IP_of_instance:8080 referencing the external IP or FQDN of the instance).
You can stop and clean the Tabby container in a separate shell as follows:
# find the container
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3014211d8e32 tabbyml/tabby "/opt/tabby/bin/tabb…" 31 minutes ago Up 31 minutes dazzling_kowalevski
# stop the container:
docker stop 3014211d8e32 # replace id from above
3014211d8e32
# remove everything
docker system prune -a # remove all docker data; container, image, ... - be careful with this command if docker is used for other purposes
sudo rm -rf ~/.tabby/models # remove downloaded model
Conclusion
With todays quantization of models to 4-6 bit a high quality inference can be achieved with acceptable or even commercially attractive consumption of system resources. Ready-Made servers in the cloud are capable to run your own inference of a multitude of models covering different use cases from programming, story telling and general inference. Let us know if you have any suggestions!
Outlook
- We are looking into further integration of interesting tools like:
- Text generation web UI, A Gradio web UI for Large Language Models which allows training of QLoRAs as well
- ExLlamaV2, an inference library for running local LLMs on modern consumer GPUs and support for Quantization with mixed-precision. It can aggressively lower the precision of the model where it has less impact
- Skypilot, Run LLMs and AI on Any Cloud and optimize your cost
- Further information about e.g. monitoring the inference or running on CPU memory only can be found in this article: How to run a 70B Neural Network on a Standard Server